Following the idea discussed in the previous blog post of what is needed to develop a system for authors’ data exchange we would like to expand on the topic after receiving feedback. In that blog post the system used for comparison is the one used in the airline industry (GDS). The comparison is not meant to imply that the system needs to be built on similar standards as in the airline industry. It is referenced simply due to one specific feature -- exchange and verification of data in real time. The current need to solve the identity management/authority control problem leads us to name the system “GDS system for authors information exchange”, but similar problems are known in other areas. This system can easily be extended to solve those problems. Some of the known problems include resolving the issues around corporate bodies/organizations names as well as subject headings from different controlled vocabularies.
We discussed just the authors for the time being but we perceive that the system would be able to exchange information about other entities (organizations/corporate bodies; controlled vocabularies [matching same terms in different vocabularies as they do not overlap]).
This system would be comprised of hubs where all stakeholders would engage in exchange/verification of information about authors. It would be a decentralized system that joins together various software instances so that everyone would be able to see the activities in all of the hubs. As we noted in the previous blog post all identified stakeholders already have experience in working on system integrations, library catalogs, institutional repositories, metadata aggregators, personal identifiers systems, publishers, and vendors, individually or otherwise hosted profiles, and on developing standards and protocols. These stakeholders are individuals, libraries, vendors, publishers, identity providers, OCLC, just to name a few. The proposed solution to the present challenge is a shared information pipeline where all of these stakeholders/agents will be able to share and exchange data about authors. Publishers, vendors, OCLC, libraries, and other stakeholders would have access to and contribute with their own information. This would enable real time data exchange. If someone updates their profile and lets the server know then anyone else interested in keeping up with the profile changes could either pull information from this server from time to time, or the server could have a subscription system that would enable subscribers to see the changes to the profile. There are currently two possibilities to explore and they include ActivityPub and/or WebSub.
As originally envisioned, each system would keep their data intact but could share the relevant information with other systems that relate to each author. To compare with a use case from the airline industry, there is a similarity to the situation when a person books a multi leg flight with multiple airline carriers via Expedia. At this point all the person data is shared with all of the different airlines in order to verify the person info. This approach ventures towards ActivityPub.
After consulting relevant documentation we recommend WebSub for further exploration as the most optimal solution to the problem we present. WebSub is a HTTP-based publish/subscribe protocol. According to the document on the w3 site, “WebSub provides a common mechanism for communication between publishers of any kind of Web content and their subscribers, based on HTTP web hooks. Subscription requests are relayed through hubs, which validate and verify the request. Hubs then distribute new and updated content to subscribers when it becomes available. WebSub was previously known as PubSubHubbub.” WebSub would provide an environment where each party could posts its evolving version of a description on a channel to which all parties subscribe. Each party would be able to gather the information they need from that channel. In this environment there is no central/correct/unique version of the data -- instead there are many versions that are informed by work being done in different institutions/applications that manage and use identity information. This is a real time information channel fed by and consumed by institutions and applications that manage and use identity information. ResourceSync Change Notifications can be used to create/update/delete links when information about a new or updated description is sent via the URI of the description. The nature of the change (create, update, or delete) and the associated URI are sent through Change Notification Channels as Change Notifications. These notifications “are sent to inform Destinations about resource change events, specifically, when a Source's resource that is subject to synchronization is created, updated, or deleted.” Further details are described in the ResourceSync Framework Specification (ANSI/NISO Z39.99-2017). ResourceSync Change Notification is based on WebSub and software for it already exists.
WebSub specifications can accommodate all the aspects of the proposed GDS system. It is important to note and map the terms used in our proposed GDS system and the ones used in WebSub.
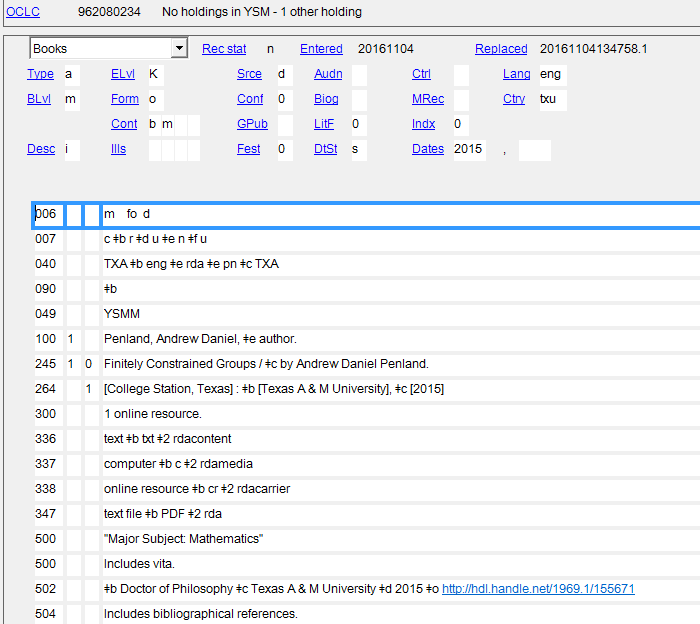
The first screenshot demonstrates a bibliographic record of a thesis written by Andrew Penland. According to the bibliographic record it appears that this person doesn’t have a name authority record created in the Library of Congress Name Authority File (LC/NAF) since his name is not controlled [see figure 1]. As noted on the OCLC Connexion Client Guides on Authorities “control headings in bibliographic records; that is, link heading(s) directly to matching Library of Congress authority record(s), if available. You can control headings in a bibliographic record in WorldCat or a record or workform in the online or local bibliographic save file (while logged on).” Additional details about controlling name headings in OCLC WorldCat Record Manager are available on the WorldShare Record Manager site where a useful video demonstrates the workflow.
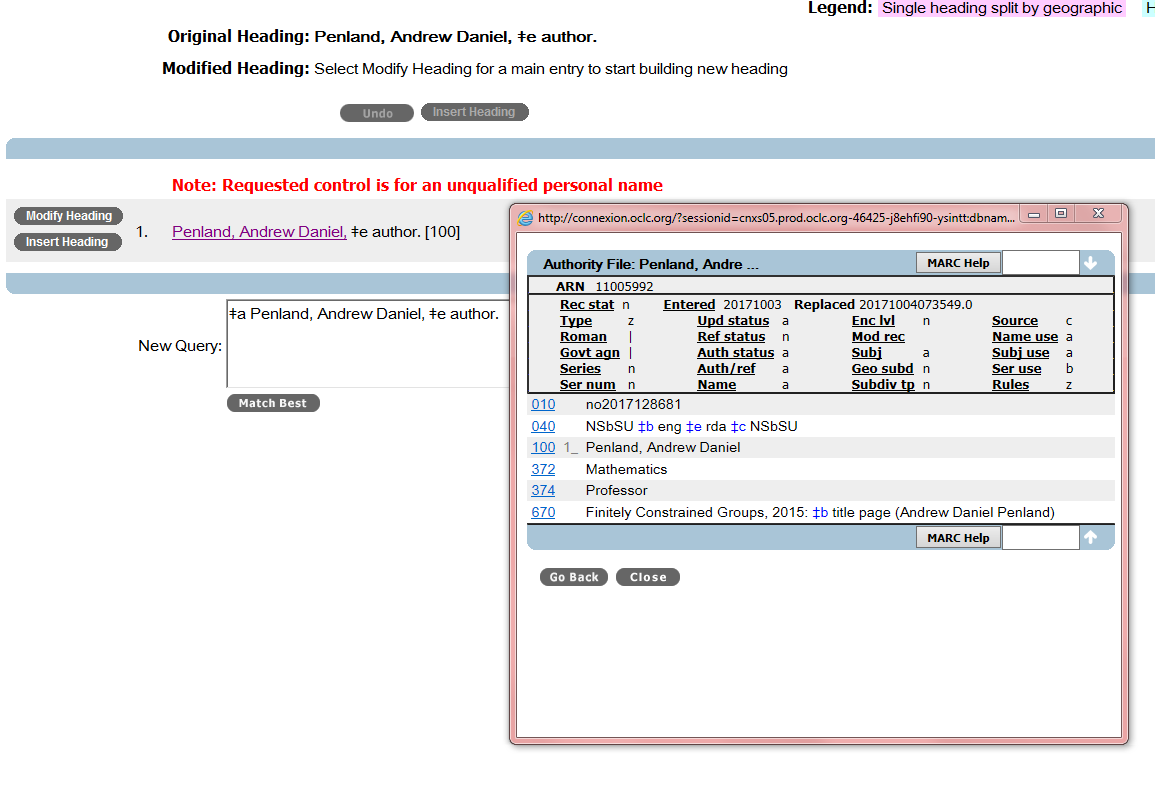
If the librarian attempts to control the heading the pop up window from OCLC suggests possible matches. The librarian needs to use judgment to determine if the suggested name is indeed the name of the author. Note that, currently, suggestions come only from one file, the Library of Congress Name Authority File (LC/NAF) [see figure 2]. It would be beneficial if the librarian is able to get hints and suggestions from other systems that may have the name of this person, or his/her identifier. It can be ORCiD, ISNI, Wikipedia entry, Scopus.
This author happens to have a Name Authority Record (NAR) created and the librarian can add it to the bibliographic record shown in figure 2. The librarian can work on enhancing the record and add more information to his record by utilizing the tool called Authority Toolkit developed by Gary Strawn from Northwestern University Libraries. This toolkit can work alongside with OCLC. The current sources that are integrated in this Toolkit include Wikidata, Wikipedia, OpenVIVO, AAT (Getty), VIAF, MeSH, LC Linked Data Services, GeoNames, TGN (Getty), ULAN (Getty), Other, Z39.50.
Another example that can demonstrate a different use case is to look at a record for a corporate body. What information can be added to the authority record for a corporate body, in this case the Simons Center for Geometry and Physics:
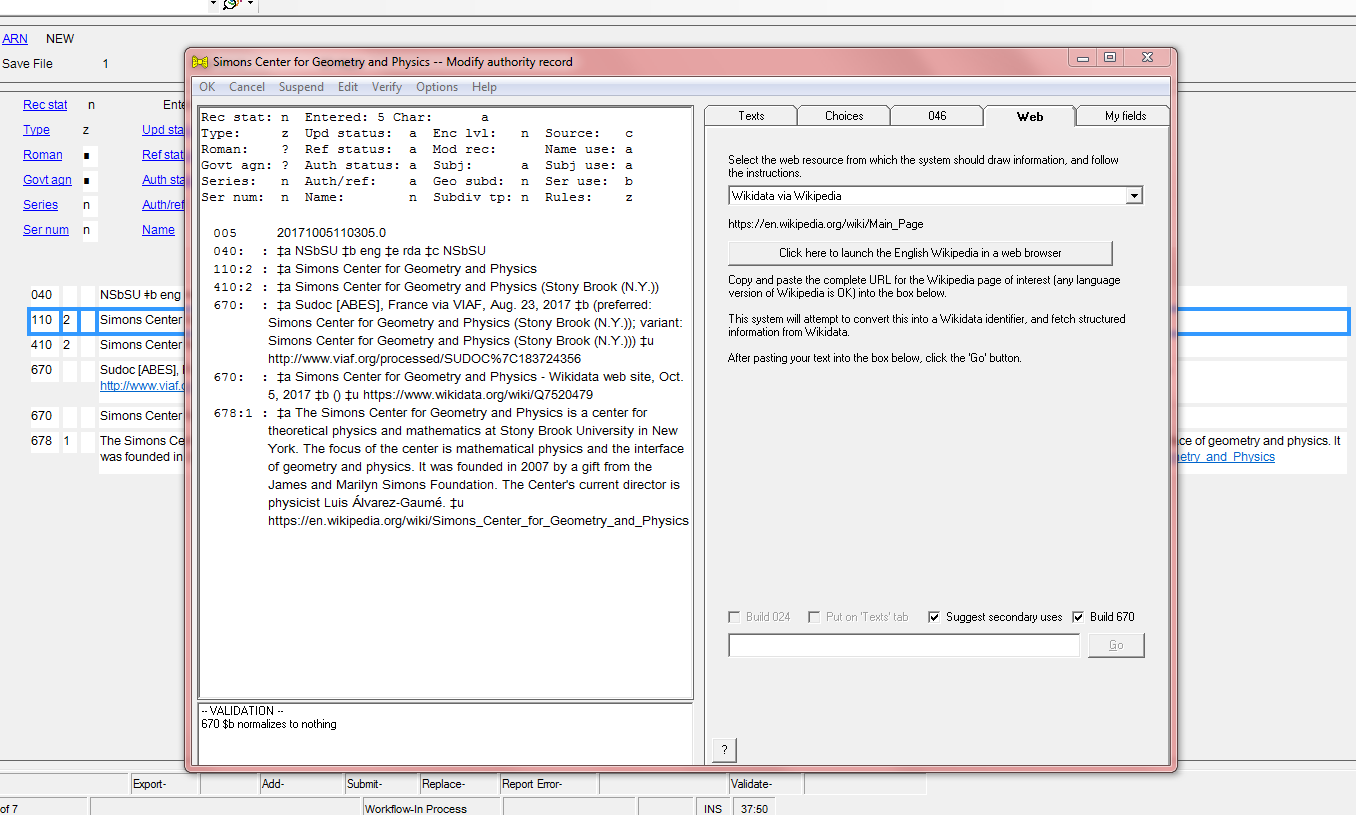
Authority Toolkit already empowers librarians to add data from different sources as mentioned above. In the case of Simmons Center for Geometry and Physics additional data are added to the NAF by utilizing the Authority Toolkit, more specifically data from VIAF, Wikidata, and Wikipedia. This tool needs to be utilized on a much more robust level to enable a more automated approach to enhancing and/or creating NAR directly from data sources such as ORCID, Wikidata, etc for use in bibliographic data via OCLC and possibly via Wikidata.
As one can see these two examples demonstrate the current tools librarians can use to find information about people and corporate bodies. The process, even though enabled by OCLC and the Authority Toolkit, is semi-manual as calling out the outside sources via the Authority Toolkit requires manually searching those sources. For example after the launch of the Wikidata site, or any other online service, one needs to enter the search terms manually. Developing a system that would follow the WebSub specifications would provide a more efficient workflow, more authoritative data from other trustworthy data sources, and would enable data sharing between trusted sources.
All organizations that manage identity information (LoC, OCLC, ORCID, DBpedia, WikiData, libraries, museums, archives, library system vendors) should have a clear interest in deploying an information sharing pipeline. The most important motivator for all of these organizations to agree on an information sharing pipeline is that all of them would need to work with only one API which would be based on the WebSub protocol. The benefits for all the organizations mentioned above are clear.
Violeta Ilik
@azraiekv
Acknowledgment: The author would like to acknowledge Sarven Capadisli, Herbert Van de Sompel, and Lukas Koster for their constructive feedback on this idea.
We discussed just the authors for the time being but we perceive that the system would be able to exchange information about other entities (organizations/corporate bodies; controlled vocabularies [matching same terms in different vocabularies as they do not overlap]).
This system would be comprised of hubs where all stakeholders would engage in exchange/verification of information about authors. It would be a decentralized system that joins together various software instances so that everyone would be able to see the activities in all of the hubs. As we noted in the previous blog post all identified stakeholders already have experience in working on system integrations, library catalogs, institutional repositories, metadata aggregators, personal identifiers systems, publishers, and vendors, individually or otherwise hosted profiles, and on developing standards and protocols. These stakeholders are individuals, libraries, vendors, publishers, identity providers, OCLC, just to name a few. The proposed solution to the present challenge is a shared information pipeline where all of these stakeholders/agents will be able to share and exchange data about authors. Publishers, vendors, OCLC, libraries, and other stakeholders would have access to and contribute with their own information. This would enable real time data exchange. If someone updates their profile and lets the server know then anyone else interested in keeping up with the profile changes could either pull information from this server from time to time, or the server could have a subscription system that would enable subscribers to see the changes to the profile. There are currently two possibilities to explore and they include ActivityPub and/or WebSub.
As originally envisioned, each system would keep their data intact but could share the relevant information with other systems that relate to each author. To compare with a use case from the airline industry, there is a similarity to the situation when a person books a multi leg flight with multiple airline carriers via Expedia. At this point all the person data is shared with all of the different airlines in order to verify the person info. This approach ventures towards ActivityPub.
After consulting relevant documentation we recommend WebSub for further exploration as the most optimal solution to the problem we present. WebSub is a HTTP-based publish/subscribe protocol. According to the document on the w3 site, “WebSub provides a common mechanism for communication between publishers of any kind of Web content and their subscribers, based on HTTP web hooks. Subscription requests are relayed through hubs, which validate and verify the request. Hubs then distribute new and updated content to subscribers when it becomes available. WebSub was previously known as PubSubHubbub.” WebSub would provide an environment where each party could posts its evolving version of a description on a channel to which all parties subscribe. Each party would be able to gather the information they need from that channel. In this environment there is no central/correct/unique version of the data -- instead there are many versions that are informed by work being done in different institutions/applications that manage and use identity information. This is a real time information channel fed by and consumed by institutions and applications that manage and use identity information. ResourceSync Change Notifications can be used to create/update/delete links when information about a new or updated description is sent via the URI of the description. The nature of the change (create, update, or delete) and the associated URI are sent through Change Notification Channels as Change Notifications. These notifications “are sent to inform Destinations about resource change events, specifically, when a Source's resource that is subject to synchronization is created, updated, or deleted.” Further details are described in the ResourceSync Framework Specification (ANSI/NISO Z39.99-2017). ResourceSync Change Notification is based on WebSub and software for it already exists.
WebSub specifications can accommodate all the aspects of the proposed GDS system. It is important to note and map the terms used in our proposed GDS system and the ones used in WebSub.
GDS terms
|
ResourceSync
|
Hub
|
Global Distribution System for authors’ information exchange (which can be expanded for information on other entities)
|
Publisher
| |
Stakeholder
|
Source
|
Subscriber
|
Agent (including the above stakeholders)
|
Destination
|
Topic
|
Authors’ information/Corporate body information channel
|
Channel
|
Subscription
|
Subscription
|
Subscriber Callback URL
| |
Event
| ||
Notification
| ||
Updates
|
Hub
|
Table 1: Mapping of GDS, ResourceSync, and WebSub terminology
As described in the WebSub document the high-level protocol flow includes the following:
- Publishers notify their hub(s) URLs when their topic(s) change.
- Subscribers POST to one or more of the advertised hubs for a topic they're interested in.
- When the hub identifies a change in the topic, it sends a notification to all registered subscribers.
Current state in library land
The following screenshots demonstrate the current workflow librarians face when working with just one file for names of people [and organizations].The first screenshot demonstrates a bibliographic record of a thesis written by Andrew Penland. According to the bibliographic record it appears that this person doesn’t have a name authority record created in the Library of Congress Name Authority File (LC/NAF) since his name is not controlled [see figure 1]. As noted on the OCLC Connexion Client Guides on Authorities “control headings in bibliographic records; that is, link heading(s) directly to matching Library of Congress authority record(s), if available. You can control headings in a bibliographic record in WorldCat or a record or workform in the online or local bibliographic save file (while logged on).” Additional details about controlling name headings in OCLC WorldCat Record Manager are available on the WorldShare Record Manager site where a useful video demonstrates the workflow.
Figure 1: Name heading not controlled
If the librarian attempts to control the heading the pop up window from OCLC suggests possible matches. The librarian needs to use judgment to determine if the suggested name is indeed the name of the author. Note that, currently, suggestions come only from one file, the Library of Congress Name Authority File (LC/NAF) [see figure 2]. It would be beneficial if the librarian is able to get hints and suggestions from other systems that may have the name of this person, or his/her identifier. It can be ORCiD, ISNI, Wikipedia entry, Scopus.
Figure 2: Suggestion for controlling the name heading
This author happens to have a Name Authority Record (NAR) created and the librarian can add it to the bibliographic record shown in figure 2. The librarian can work on enhancing the record and add more information to his record by utilizing the tool called Authority Toolkit developed by Gary Strawn from Northwestern University Libraries. This toolkit can work alongside with OCLC. The current sources that are integrated in this Toolkit include Wikidata, Wikipedia, OpenVIVO, AAT (Getty), VIAF, MeSH, LC Linked Data Services, GeoNames, TGN (Getty), ULAN (Getty), Other, Z39.50.
Another example that can demonstrate a different use case is to look at a record for a corporate body. What information can be added to the authority record for a corporate body, in this case the Simons Center for Geometry and Physics:
Figure 3: Adding information from Wikidata and Wikipedia to the record
Authority Toolkit already empowers librarians to add data from different sources as mentioned above. In the case of Simmons Center for Geometry and Physics additional data are added to the NAF by utilizing the Authority Toolkit, more specifically data from VIAF, Wikidata, and Wikipedia. This tool needs to be utilized on a much more robust level to enable a more automated approach to enhancing and/or creating NAR directly from data sources such as ORCID, Wikidata, etc for use in bibliographic data via OCLC and possibly via Wikidata.
As one can see these two examples demonstrate the current tools librarians can use to find information about people and corporate bodies. The process, even though enabled by OCLC and the Authority Toolkit, is semi-manual as calling out the outside sources via the Authority Toolkit requires manually searching those sources. For example after the launch of the Wikidata site, or any other online service, one needs to enter the search terms manually. Developing a system that would follow the WebSub specifications would provide a more efficient workflow, more authoritative data from other trustworthy data sources, and would enable data sharing between trusted sources.
Benefits
One obvious benefit would be that all stakeholders would be able to look up information about authors in one place, since the information that comes from various data sources would be synchronized. Next, even if the information about a person is stored on a personal server, if it’s stored according to standards, such as the ones supported by w3c (w3id.org), after the person ceases to maintain the personal server, for any reason, a copy of the data could be found in the GDS system and or in the other software systems and would not be lost.All organizations that manage identity information (LoC, OCLC, ORCID, DBpedia, WikiData, libraries, museums, archives, library system vendors) should have a clear interest in deploying an information sharing pipeline. The most important motivator for all of these organizations to agree on an information sharing pipeline is that all of them would need to work with only one API which would be based on the WebSub protocol. The benefits for all the organizations mentioned above are clear.
Violeta Ilik
@azraiekv
Acknowledgment: The author would like to acknowledge Sarven Capadisli, Herbert Van de Sompel, and Lukas Koster for their constructive feedback on this idea.
Most valuable article. Really I got more knowledge from this article. Thanks.
ReplyDeleteSpring Training in Chennai
Spring and Hibernate Training in Chennai
Spring Training in Adyar
Hibernate Training in Chennai
Spring and Hibernate Training
Struts Training in Chennai
Wordpress Training in Chennai
Spring Training in Chennai
Very informative blog! I am glad that I came across your article. I'm learning a lot from here. Keep us updated by sharing more such blogs.
ReplyDeleteAWS Training in Chennai
AWS Course
DevOps Training in Chennai
VMware course in Chennai
Microsoft Azure Training in Chennai
Cloud Computing Courses in Chennai
Amazon web services Training in Chennai
Best AWS Training in Chennai
AWS Training in Velachery
Thanks for this great post, i find it very interesting and very well thought out and put together. I look forward to reading your work in the future. Hire a Copywriter
ReplyDeleteI am continually amazed by the amount of information available on this subject. What you presented was well researched and well worded in order to get your stand on this across to all your readers. Direct Response Copywriter
ReplyDeletebetmatik
ReplyDeletekralbet
betpark
tipobet
slot siteleri
kibris bahis siteleri
poker siteleri
bonus veren siteler
mobil ödeme bahis
0İG
شركة عزل اسطح وخزانات بالاحساء
ReplyDeleteY7vEaUaFoMQP
شركة مكافحة حشرات بجدة
ReplyDelete